import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
Show code cell content
# Plot style
sns.set()
%pylab inline
pylab.rcParams['figure.figsize'] = (4, 4)
# Avoid inaccurate floating values (for inverse matrices in dot product for instance)
# See https://stackoverflow.com/questions/24537791/numpy-matrix-inversion-rounding-errors
np.set_printoptions(suppress=True)
Populating the interactive namespace from numpy and matplotlib
Show code cell content
def plotVectors(vecs, cols, alpha=1):
"""
Plot set of vectors.
Parameters
----------
vecs : array-like
Coordinates of the vectors to plot. Each vectors is in an array. For
instance: [[1, 3], [2, 2]] can be used to plot 2 vectors.
cols : array-like
Colors of the vectors. For instance: ['red', 'blue'] will display the
first vector in red and the second in blue.
alpha : float
Opacity of vectors
Returns:
fig : instance of matplotlib.figure.Figure
The figure of the vectors
"""
plt.axvline(x=0, color='#A9A9A9', zorder=0)
plt.axhline(y=0, color='#A9A9A9', zorder=0)
for i in range(len(vecs)):
if (isinstance(alpha, list)):
alpha_i = alpha[i]
else:
alpha_i = alpha
x = np.concatenate([[0,0],vecs[i]])
plt.quiver([x[0]],
[x[1]],
[x[2]],
[x[3]],
angles='xy', scale_units='xy', scale=1, color=cols[i],
alpha=alpha_i)
2.7 Eigendecomposition#
We will see some major concepts of linear algebra in this chapter. It is also quite heavy so hang on! We will start with getting some ideas on eigenvectors and eigenvalues. We will develop on the idea that a matrix can be seen as a linear transformation and that applying a matrix on its eigenvectors gives new vectors with the same direction. Then we will see how to express quadratic equations into the matrix form. We will see that the eigendecomposition of the matrix corresponding to a quadratic equation can be used to find the minimum and maximum of this function. As a bonus, we will also see how to visualize linear transformations in Python!
The eigendecomposition is one form of matrix decomposition. Decomposing a matrix means that we want to find a product of matrices that is equal to the initial matrix. In the case of the eigendecomposition, we decompose the initial matrix into the product of its eigenvectors and eigenvalues. Before all, let’s see what are eigenvectors and eigenvalues.
Matrices as linear transformations#
As we have seen in previous sections with the example of the identity matrix, you can think of matrices as linear transformations. Some matrices will rotate your space, others will rescale it etc. So when we apply a matrix to a vector, we end up with a transformed version of the vector. When we say that we ‘apply’ the matrix to the vector it means that we calculate the dot product of the matrix with the vector. We will start with a basic example of this kind of transformation.
Example 1.#
A = np.array([[-1, 3], [2, -2]])
A
array([[-1, 3],
[ 2, -2]])
v = np.array([[2], [1]])
v
array([[2],
[1]])
Let’s plot this vector:
plotVectors([v.flatten()], cols=['#1190FF'])
plt.ylim(-1, 4)
plt.xlim(-1, 4)
(-1, 4)
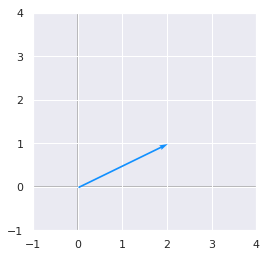
Now, we will apply the matrix \(\bs{A}\) to this vector and plot the old vector (light blue) and the new one (orange):
Av = A.dot(v)
print(Av)
plotVectors([v.flatten(), Av.flatten()], cols=['#1190FF', '#FF9A13'])
plt.ylim(-1, 4)
plt.xlim(-1, 4)
[[1]
[2]]
(-1, 4)
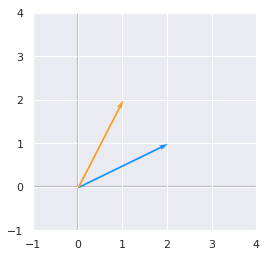
We can see that applying the matrix \(\bs{A}\) has the effect of modifying the vector.
Now that you can think of matrices as linear transformation recipes, let’s see the case of a very special type of vector: the eigenvector.
Eigenvectors and eigenvalues#
We have seen an example of a vector transformed by a matrix. Now imagine that the transformation of the initial vector gives us a new vector that has the exact same direction. The scale can be different but the direction is the same. Applying the matrix didn’t change the direction of the vector. This special vector is called an eigenvector of the matrix. We will see that finding the eigenvectors of a matrix can be very useful.
Imagine that the transformation of the initial vector by the matrix gives a new vector with the exact same direction. This vector is called an eigenvector of $\bs{A}$.This means that \(\bs{v}\) is a eigenvector of \(\bs{A}\) if \(\bs{v}\) and \(\bs{Av}\) are in the same direction or to rephrase it if the vectors \(\bs{Av}\) and \(\bs{v}\) are parallel. The output vector is just a scaled version of the input vector. This scalling factor is \(\lambda\) which is called the eigenvalue of \(\bs{A}\).
Example 2.#
Let’s \(\bs{A}\) be the following matrix:
We know that one eigenvector of A is:
We can check that \(\bs{Av} = \lambda\bs{v}\):
We can see that:
which means that \(\bs{v}\) is well an eigenvector of \(\bs{A}\). Also, the corresponding eigenvalue is \(\lambda=6\).
We can represent \(\bs{v}\) and \(\bs{Av}\) to check if their directions are the same:
A = np.array([[5, 1], [3, 3]])
A
array([[5, 1],
[3, 3]])
v = np.array([[1], [1]])
v
array([[1],
[1]])
Av = A.dot(v)
orange = '#FF9A13'
blue = '#1190FF'
plotVectors([Av.flatten(), v.flatten()], cols=[blue, orange])
plt.ylim(-1, 7)
plt.xlim(-1, 7)
(-1, 7)
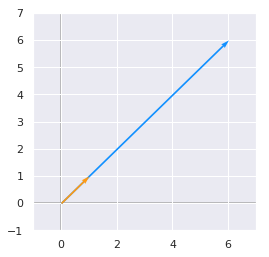
We can see that their directions are the same!
Another eigenvector of \(\bs{A}\) is
because
and
So the corresponding eigenvalue is \(\lambda=2\).
v = np.array([[1], [-3]])
v
array([[ 1],
[-3]])
Av = A.dot(v)
plotVectors([Av.flatten(), v.flatten()], cols=[blue, orange])
plt.ylim(-7, 1)
plt.xlim(-1, 3)
(-1, 3)
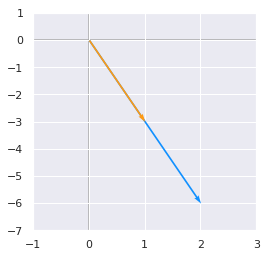
This example shows that the eigenvectors \(\bs{v}\) are vectors that change only in scale when we apply the matrix \(\bs{A}\) to them. Here the scales were 6 for the first eigenvector and 2 to the second but \(\lambda\) can take any real or even complex value.
Find eigenvalues and eigenvectors in Python#
Numpy provides a function returning eigenvectors and eigenvalues (the first array corresponds to the eigenvalues and the second to the eigenvectors concatenated in columns):
(array([ 6., 2.]), array([[ 0.70710678, -0.31622777],
[ 0.70710678, 0.9486833 ]]))
Here a demonstration with the preceding example.
A = np.array([[5, 1], [3, 3]])
A
array([[5, 1],
[3, 3]])
np.linalg.eig(A)
(array([6., 2.]), array([[ 0.70710678, -0.31622777],
[ 0.70710678, 0.9486833 ]]))
We can see that the eigenvalues are the same than the ones we used before: 6 and 2 (first array).
The eigenvectors correspond to the columns of the second array. This means that the eigenvector corresponding to \(\lambda=6\) is:
The eigenvector corresponding to \(\lambda=2\) is:
The eigenvectors look different because they have not necessarly the same scaling than the ones we gave in the example. We can easily see that the first corresponds to a scaled version of our \(\begin{bmatrix} 1\\\\ 1 \end{bmatrix}\). But the same property stands. We have still \(\bs{Av} = \lambda\bs{v}\):
With \(0.70710678 \times 6 = 4.24264069\). So there are an infinite number of eigenvectors corresponding to the eigenvalue \(6\). They are equivalent because we are interested by their directions.
For the second eigenvector we can check that it corresponds to a scaled version of \(\begin{bmatrix} 1\\\\ -3 \end{bmatrix}\). We can draw these vectors and see if they are parallel.
v = np.array([[1], [-3]])
Av = A.dot(v)
v_np = [-0.31622777, 0.9486833]
plotVectors([Av.flatten(), v.flatten(), v_np], cols=[blue, orange, 'blue'])
plt.ylim(-7, 1)
plt.xlim(-1, 3)
(-1, 3)
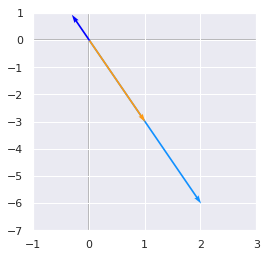
We can see that the vector found with Numpy (in dark blue) is a scaled version of our preceding \(\begin{bmatrix} 1\\\\ -3 \end{bmatrix}\).
Rescaled vectors#
As we saw it with numpy, if \(\bs{v}\) is an eigenvector of \(\bs{A}\), then any rescaled vector \(s\bs{v}\) is also an eigenvector of \(\bs{A}\). The eigenvalue of the rescaled vector is the same.
Let’s try to rescale
from our preceding example.
For instance,
We have well \(\bs{A}\times 3\bs{v} = \lambda\bs{v}\) and the eigenvalue is still \(\lambda=2\).
Concatenating eigenvalues and eigenvectors#
Now that we have an idea of what eigenvectors and eigenvalues are we can see how it can be used to decompose a matrix. All eigenvectors of a matrix \(\bs{A}\) can be concatenated in a matrix with each column corresponding to each eigenvector (like in the second array return by np.linalg.eig(A)):
The first column \( \begin{bmatrix} 1\\\\ 1 \end{bmatrix} \) corresponds to \(\lambda=6\) and the second \( \begin{bmatrix} 1\\\\ -3 \end{bmatrix} \) to \(\lambda=2\).
The vector \(\bs{\lambda}\) can be created from all eigenvalues:
Then the eigendecomposition is given by
We can decompose the matrix \(\bs{A}\) with eigenvectors and eigenvalues. It is done with: \(\bs{A}=\bs{V}\cdot diag(\bs{\lambda}) \cdot \bs{V}^{-1}\)
\(diag(\bs{v})\) is a diagonal matrix containing all the eigenvalues. Continuing with our example we have
The diagonal matrix is all zeros except the diagonal that is our vector \(\bs{\lambda}\).
The inverse matrix of \(\bs{V}\) can be calculated with numpy:
V = np.array([[1, 1], [1, -3]])
V
array([[ 1, 1],
[ 1, -3]])
V_inv = np.linalg.inv(V)
V_inv
array([[ 0.75, 0.25],
[ 0.25, -0.25]])
So let’s plug
into our equation:
If we do the dot product of the first two matrices we have:
So with replacing into the equation:
Let’s check our result with Python:
lambdas = np.diag([6,2])
lambdas
array([[6, 0],
[0, 2]])
V.dot(lambdas).dot(V_inv)
array([[5., 1.],
[3., 3.]])
That confirms our previous calculation.
Real symmetric matrix#
In the case of real symmetric matrices (more details about symmetric matrices in previous section), the eigendecomposition can be expressed as
where \(\bs{Q}\) is the matrix with eigenvectors as columns and \(\Lambda\) is \(diag(\lambda)\).
Example 3.#
This matrix is symmetric because \(\bs{A}=\bs{A}^\text{T}\). Its eigenvectors are:
and its eigenvalues put in a diagonal matrix gives:
So let’s begin to calculate \(\bs{Q\Lambda}\):
with:
So we have:
It works! For that reason, it can useful to use symmetric matrices! Let’s do the same things easily with linalg from numpy:
A = np.array([[6, 2], [2, 3]])
A
array([[6, 2],
[2, 3]])
eigVals, eigVecs = np.linalg.eig(A)
eigVecs
array([[ 0.89442719, -0.4472136 ],
[ 0.4472136 , 0.89442719]])
eigVals = np.diag(eigVals)
eigVals
array([[7., 0.],
[0., 2.]])
eigVecs.dot(eigVals).dot(eigVecs.T)
array([[6., 2.],
[2., 3.]])
We can see that the result corresponds to our initial matrix.
Quadratic form to matrix form#
Eigendecomposition can be used to optimize quadratic functions. We will see that when \(\bs{x}\) takes the values of an eigenvector, \(f(\bs{x})\) takes the value of its corresponding eigenvalue.
When $\bs{x}$ takes the values of an eigenvector, $f(\bs{x})$ takes the value of its corresponding eigenvalue.We will see in the following points how we can show that with different methods.
Let’s have the following quadratic equation:
These quadratic forms can be generated by matrices:
with:
and
We call them matrix forms. This form is useful to do various things on the quadratic equation like constrained optimization (see bellow).
Quadratic equations can be expressed under the matrix formIf you look at the relation between these forms you can see that \(a\) gives you the number of \(x_1^2\), \((b + c)\) the number of \(x_1x_2\) and \(d\) the number of \(x_2^2\). This means that the same quadratic form can be obtained from infinite number of matrices \(\bs{A}\) by changing \(b\) and \(c\) while preserving their sum.
Example 4.#
and
gives the following quadratic form:
but if:
we still have the quadratic same form:
Example 5#
For this example, we will go from the matrix form to the quadratic form using a symmetric matrix \(\bs{A}\). Let’s use the matrix of the example 3.
and
Our quadratic equation is thus \(6 x_1^2 + 4 x_1x_2 + 3 x_2^2\).
Note#
If \(\bs{A}\) is a diagonal matrix (all 0 except the diagonal), the quadratic form of \(\bs{x^\text{T}Ax}\) will have no cross term. Take the following matrix form:
If \(\bs{A}\) is diagonal, then \(b\) and \(c\) are 0 and since \(f(\bs{x}) = ax_1^2 +(b+c)x_1x_2 + dx_2^2\) there is no cross term. A quadratic form without cross term is called diagonal form since it comes from a diagonal matrix.
Change of variable#
A change of variable (or linear substitution) simply means that we replace a variable by another one. We will see that it can be used to remove the cross terms in our quadratic equation. Without the cross term, it will then be easier to characterize the function and eventually optimize it (i.e finding its maximum or minimum).
With the quadratic form#
Example 6.#
Let’s take again our previous quadratic form:
The change of variable will concern \(x_1\) and \(x_2\). We can replace \(x_1\) with any combination of \(y_1\) and \(y_2\) and \(x_2\) with any combination \(y_1\) and \(y_2\). We will of course end up with a new equation. The nice thing is that we can find a specific substitution that will lead to a simplification of our statement. Specifically, it can be used to get rid of the cross term (in our example: \(4 x_1x_2\)). We will see later why it is interesting.
Actually, the right substitution is given by the eigenvectors of the matrix used to generate the quadratic form. Let’s recall that the matrix form of our equation is:
and
and that the eigenvectors of \(\bs{A}\) are:
With the purpose of simplification, we can replace these values with:
So our first eigenvector is:
and our second eigenvector is:
The change of variable will lead to:
so we have
So far so good! Let’s replace that in our example:
That’s great! Our new equation doesn’t have any cross terms!
With the Principal Axes Theorem#
Actually there is a simpler way to do the change of variable. We can stay in the matrix form. Recall that we start with the form:
The linear substitution can be wrote in these terms. We want replace the variables \(\bs{x}\) by \(\bs{y}\) that relates by:
We want to find \(P\) such as our new equation (after the change of variable) doesn’t contain the cross terms. The first step is to replace that in the first equation:
Can you see the how to transform the left hand side (\(\bs{x}\)) into the right hand side (\(\bs{y}\))? The substitution is done by replacing \(\bs{A}\) with \(\bs{P^\text{T}AP}\). We also know that \(\bs{A}\) is symmetric and thus that there is a diagonal matrix \(\bs{D}\) containing the eigenvectors of \(\bs{A}\) and such as \(\bs{D}=\bs{P}^\text{T}\bs{AP}\). We thus end up with:
All of this implies that we can use \(\bs{D}\) to simplify our quadratic equation and remove the cross terms. If you remember from example 2 we know that the eigenvalues of \(\bs{A}\) are:
That’s nice! If you look back to the change of variable that we have done in the quadratic form, you will see that we have found the same values!
This form (without cross-term) is called the principal axes form.
Summary#
To summarise, the principal axes form can be found with
where \(\lambda_1\) is the eigenvalue corresponding to the first eigenvector and \(\lambda_2\) the eigenvalue corresponding to the second eigenvector (second column of \(\bs{x}\)).
Finding f(x) with eigendecomposition#
We will see that there is a way to find \(f(\bs{x})\) with eigenvectors and eigenvalues when \(\bs{x}\) is a unit vector.
Let’s start from:
We know that if \(\bs{x}\) is an eigenvector of \(\bs{A}\) and \(\lambda\) the corresponding eigenvalue, then \( \bs{Ax}=\lambda \bs{x} \). By replacing the term in the last equation we have:
Since \(\bs{x}\) is a unit vector, \(\norm{\bs{x}}_2=1\) and \(\bs{x^\text{T}x}=1\). We end up with
This is a usefull property. If \(\bs{x}\) is an eigenvector of \(\bs{A}\), \( f(\bs{x}) =\bs{x^\text{T}Ax}\) will take the value of the corresponding eigenvalue. We can see that this is working only if the euclidean norm of \(\bs{x}\) is 1 (i.e \(\bs{x}\) is a unit vector).
Example 7#
This example will show that \(f(\bs{x}) = \lambda\). Let’s take again the last example, the eigenvectors of \(\bs{A}\) were
and the eigenvalues
So if:
\(f(\bs{x})\) should be equal to 7. Let’s check that’s true.
In the same way, if \(\bs{x}=\begin{bmatrix} -0.4472136 & 0.89442719 \end{bmatrix}\), \(f(\bs{x})\) should be equal to 2.
Quadratic form optimization#
Depending to the context, optimizing a function means finding its maximum or its minimum. It is for instance widely used to minimize the error of cost functions in machine learning.
Here we will see how eigendecomposition can be used to optimize quadratic functions and why this can be done easily without cross terms. The difficulty is that we want a constrained optimization, that is to find the minimum or the maximum of the function for \(f(\bs{x})\) being a unit vector.
Example 7.#
We want to optimize:
In our last example we ended up with:
And the constraint of \(\bs{x}\) being a unit vector imply:
We can also show that \(\bs{y}\) has to be a unit vector if it is the case for \(\bs{x}\). Recall first that \(\bs{x}=\bs{Py}\):
So \(\norm{\bs{x}}^2 = \norm{\bs{y}}^2 = 1\) and thus \(y_1^2 + y_2^2 = 1\)
Since \(y_1^2\) and \(y_2^2\) cannot be negative because they are squared values, we can be sure that \(2y_2^2\leq7y_2^2\). Hence:
This means that the maximum value of \(f(\bs{x})\) is 7.
The same way can lead to find the minimum of \(f(\bs{x})\). \(7y_1^2\geq2y_1^2\) and:
And the minimum of \(f(\bs{x})\) is 2.
Summary#
We can note that the minimum of \(f(\bs{x})\) is the minimum eigenvalue of the corresponding matrix \(\bs{A}\). Another useful fact is that this value is obtained when \(\bs{x}\) takes the value of the corresponding eigenvector (check back the preceding paragraph). In that way, \(f(\bs{x})=7\) when \(\bs{x}=\begin{bmatrix}0.89442719 & 0.4472136\end{bmatrix}\). This shows how useful are the eigenvalues and eigenvector in this kind of constrained optimization.
Graphical views#
We saw that the quadratic functions \(f(\bs{x}) = ax_1^2 +2bx_1x_2 + cx_2^2\) can be represented by the symmetric matrix \(\bs{A}\):
Graphically, these functions can take one of three general shapes:
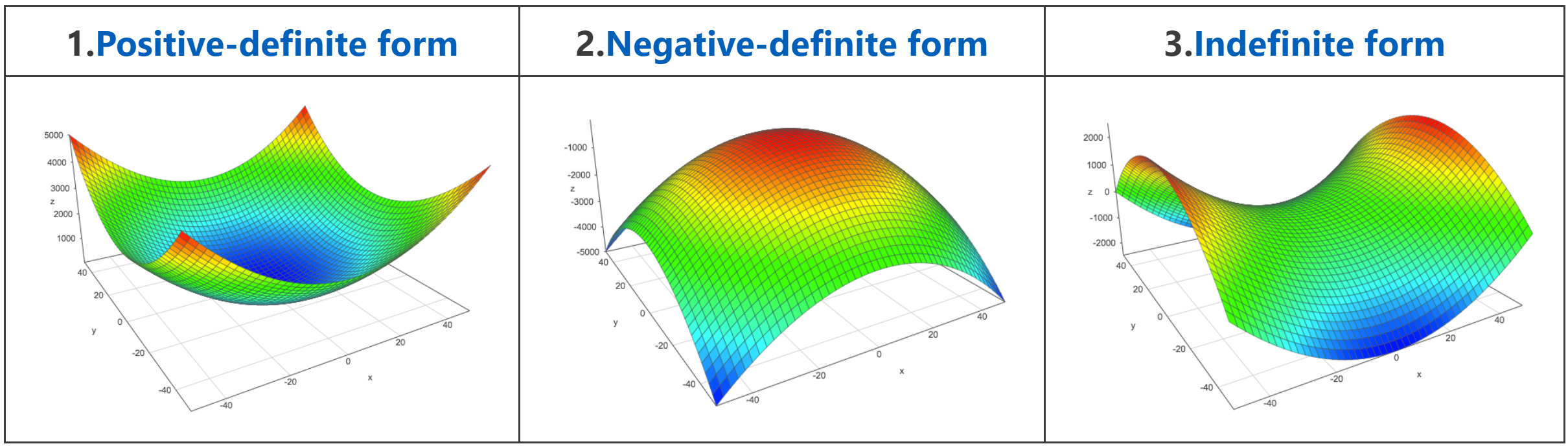
Source: Academo.org
With the constraints that \(\bs{x}\) is a unit vector, the minimum of the function \(f(\bs{x})\) corresponds to the smallest eigenvalue and is obtained with its corresponding eigenvector. The maximum corresponds to the biggest eigenvalue and is obtained with its corresponding eigenvector.
Conclusion#
We have seen a lot of things in this chapter. We saw that linear algebra can be used to solve a variety of mathematical problems and more specifically that eigendecomposition is a powerful tool! However, it cannot be used for non square matrices. In the next chapter, we will see the Singular Value Decomposition (SVD) which is another way of decomposing matrices. The advantage of the SVD is that you can use it also with non-square matrices.
BONUS: visualizing linear transformations#
We can see the effect of eigenvectors and eigenvalues in linear transformation. We will see first how linear transformation works. Linear transformation is a mapping between an input vector and an output vector. Different operations like projection or rotation are linear transformations. Every linear transformations can be though as applying a matrix on the input vector. We will see the meaning of this graphically. For that purpose, let’s start by drawing the set of unit vectors (they are all vectors with a norm of 1).
t = np.linspace(0, 2*np.pi, 100)
x = np.cos(t)
y = np.sin(t)
plt.figure()
plt.plot(x, y)
plt.xlim(-1.5, 1.5)
plt.ylim(-1.5, 1.5)
plt.show()
Then, we will transform each of these points by applying a matrix \(\bs{A}\). This is the goal of the function bellow that takes a matrix as input and will draw
the origin set of unit vectors
the transformed set of unit vectors
the eigenvectors
the eigenvectors scalled by their eigenvalues
def linearTransformation(transformMatrix):
orange = '#FF9A13'
blue = '#1190FF'
# Create original set of unit vectors
t = np.linspace(0, 2*np.pi, 100)
x = np.cos(t)
y = np.sin(t)
# Calculate eigenvectors and eigenvalues
eigVecs = np.linalg.eig(transformMatrix)[1]
eigVals = np.diag(np.linalg.eig(transformMatrix)[0])
# Create vectors of 0 to store new transformed values
newX = np.zeros(len(x))
newY = np.zeros(len(x))
for i in range(len(x)):
unitVector_i = np.array([x[i], y[i]])
# Apply the matrix to the vector
newXY = transformMatrix.dot(unitVector_i)
newX[i] = newXY[0]
newY[i] = newXY[1]
plotVectors([eigVecs[:,0], eigVecs[:,1]],
cols=[blue, blue])
plt.plot(x, y)
plotVectors([eigVals[0,0]*eigVecs[:,0], eigVals[1,1]*eigVecs[:,1]],
cols=[orange, orange])
plt.plot(newX, newY)
plt.xlim(-5, 5)
plt.ylim(-5, 5)
plt.show()
A = np.array([[1,-1], [-1, 4]])
linearTransformation(A)
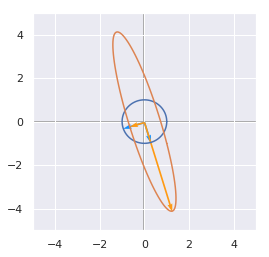
We can see the unit circle in dark blue, the non scaled eigenvectors in light blue, the transformed unit circle in green and the scaled eigenvectors in yellow.
It is worth noting that the eigenvectors are orthogonal here because the matrix is symmetric. Let’s try with a non-symmetric matrix:
A = np.array([[1,1], [-1, 4]])
linearTransformation(A)
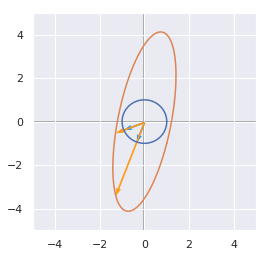
In this case, the eigenvectors are not orthogonal!