import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
Show code cell source
# Plot parameters
sns.set()
%pylab inline
pylab.rcParams['figure.figsize'] = (4, 4)
plt.rcParams['xtick.major.size'] = 0
plt.rcParams['ytick.major.size'] = 0
# Avoid inaccurate floating values (for inverse matrices in dot product for instance)
# See https://stackoverflow.com/questions/24537791/numpy-matrix-inversion-rounding-errors
np.set_printoptions(suppress=True)
Show code cell output
Populating the interactive namespace from numpy and matplotlib
2.6 Special Kinds of Matrices and Vectors#
We have seen in previous sections some interesting kind of matrices. We will see other type of vectors and matrices in this chapter. It is not a big chapter but it is important to understand the next ones.
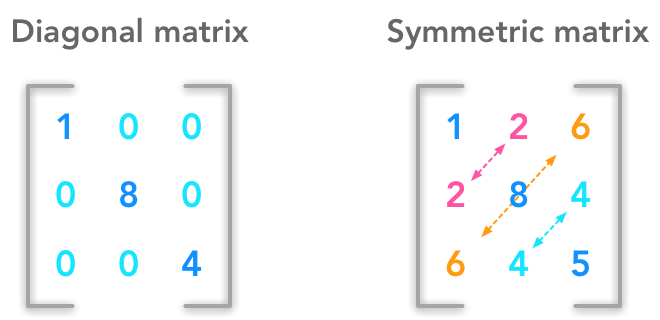
Example of diagonal and symmetric matrices
Diagonal matrices#

Example of a diagonal matrix
A matrix \(\bs{A}_{i,j}\) is diagonal if its entries are all zeros except on the diagonal (when \(i=j\)).
Example 1.#
In this case the matrix is also square but there can be non square diagonal matrices.
Example 2.#
Or
The diagonal matrix can be denoted \(diag(\bs{v})\) where \(\bs{v}\) is the vector containing the diagonal values.
Example 3.#
In this matrix, \(\bs{v}\) is the following vector:
The Numpy function diag() can be used to create square diagonal matrices:
v = np.array([2, 4, 3, 1])
np.diag(v)
array([[2, 0, 0, 0],
[0, 4, 0, 0],
[0, 0, 3, 0],
[0, 0, 0, 1]])
The mutliplication between a diagonal matrix and a vector is thus just a ponderation of each element of the vector by \(v\):
Example 4.#
and
Non square matrices have the same properties:
Example 5.#
and
The invert of a square diagonal matrix exists if all entries of the diagonal are non-zeros. If it is the case, the invert is easy to find. Also, the inverse doen’t exist if the matrix is non-square.
Let’s check with Numpy that the multiplication of the matrix with its invert gives us the identity matrix:
A = np.array([[2, 0, 0, 0], [0, 4, 0, 0], [0, 0, 3, 0], [0, 0, 0, 1]])
A
array([[2, 0, 0, 0],
[0, 4, 0, 0],
[0, 0, 3, 0],
[0, 0, 0, 1]])
A_inv = np.array([[1/2., 0, 0, 0], [0, 1/4., 0, 0], [0, 0, 1/3., 0], [0, 0, 0, 1/1.]])
A_inv
array([[0.5 , 0. , 0. , 0. ],
[0. , 0.25 , 0. , 0. ],
[0. , 0. , 0.33333333, 0. ],
[0. , 0. , 0. , 1. ]])
A.dot(A_inv)
array([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])
Great! This gives the identity matrix
Symmetric matrices#
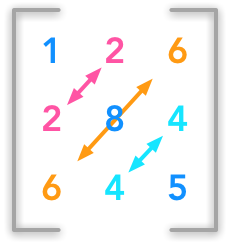
Illustration of a symmetric matrix
The matrix \(A\) is symmetric if it is equal to its transpose:
This concerns only square matrices.
Example 6.#
A = np.array([[2, 4, -1], [4, -8, 0], [-1, 0, 3]])
A
array([[ 2, 4, -1],
[ 4, -8, 0],
[-1, 0, 3]])
A.T
array([[ 2, 4, -1],
[ 4, -8, 0],
[-1, 0, 3]])
Unit vectors#
A unit vector is a vector of length equal to 1. It can be denoted by a letter with a hat: \(\hat{u}\)
Orthogonal vectors#
Two orthogonal vectors are separated by a 90° angle. The dot product of two orthogonal vectors gives 0.
Example 7.#
x = [0,0,2,2]
y = [0,0,2,-2]
plt.quiver([x[0], y[0]],
[x[1], y[1]],
[x[2], y[2]],
[x[3], y[3]],
angles='xy', scale_units='xy', scale=1)
plt.xlim(-2, 4)
plt.ylim(-3, 3)
plt.axvline(x=0, color='grey')
plt.axhline(y=0, color='grey')
plt.text(1, 1.5, r'$\vec{u}$', size=18)
plt.text(1.5, -1, r'$\vec{v}$', size=18)
plt.show()
plt.close()
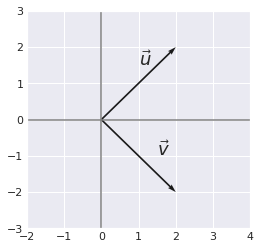
and
In addition, when the norm of orthogonal vectors is the unit norm they are called orthonormal.
It is impossible to have more than \(n\) vectors mutually orthogonal in \(\mathbb{R}^n\). For instance try to draw 3 vectors in a 2-dimensional space (\(\mathbb{R}^2\)) that are mutually orthogonal…
Orthogonal matrices#
Orthogonal matrices are important because they have interesting properties. A matrix is orthogonal if columns are mutually orthogonal and have a unit norm (orthonormal) and rows are mutually orthonormal and have unit norm.
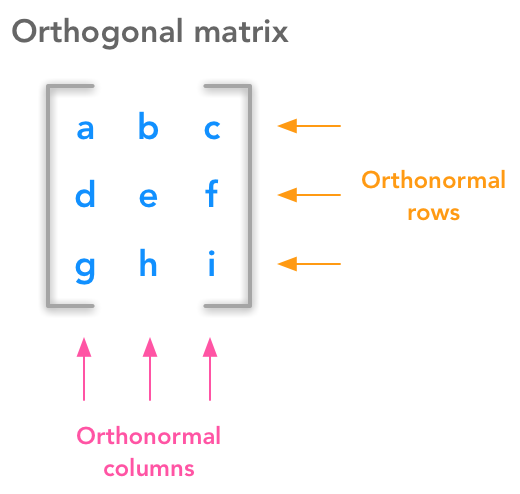
Under the hood of an orthogonal matrix
This means that
and
are orthogonal vectors and also that the rows
and
are orthogonal vectors (cf. above for definition of orthogonal vectors).
Property 1: \(\bs{A^\text{T}A}=\bs{I}\)#
A orthogonal matrix has this property:
We can see that this statement is true with the following reasoning:
Let’s have the following matrix:
and thus
Let’s do the product:
We saw that the norm of the vector \(\begin{bmatrix} a & c \end{bmatrix}\) is equal to \(a^2+c^2\) (\(L^2\) or squared \(L^2\)). In addtion, we saw that the rows of \(\bs{A}\) have a unit norm because \(\bs{A}\) is orthogonal. This means that \(a^2+c^2=1\) and \(b^2+d^2=1\). So we now have:
Also, \(ab+cd\) corresponds to the product of \(\begin{bmatrix} a & c \end{bmatrix} and \begin{bmatrix} b & d \end{bmatrix}\):
And we know that the columns are orthogonal which means that:
We thus have the identity matrix:
Property 2: \(\bs{A}^\text{T}=\bs{A}^{-1}\)#
We can show that if \(\bs{A^\text{T}A}=\bs{I}\) then \( \bs{A}^\text{T}=\bs{A}^{-1}\).
If we multiply each side of the equation \(\bs{A^\text{T}A}=\bs{I}\) by \(\bs{A}^{-1}\) we have:
Recall that a matrix or vector doesn’t change when it is multiplied by the identity matrix. So we have:
We also saw that matrix multiplication is associative so we can remove the parenthesis:
We also know that \(\bs{A}\bs{A}^{-1}=\bs{I}\) so we can replace:
This shows that
You can refer to this question.
Example 8.#
Sine and cosine are convenient to create orthogonal matrices. Let’s take the following matrix:
A = np.array([[np.cos(50), -np.sin(50)], [np.sin(50), np.cos(50)]])
A
array([[ 0.96496603, 0.26237485],
[-0.26237485, 0.96496603]])
col0 = A[:, [0]]
col1 = A[:, [1]]
row0 = A[0].reshape(A.shape[1], 1)
row1 = A[1].reshape(A.shape[1], 1)
Let’s check that rows and columns are orthogonal:
col0.T.dot(col1)
array([[0.]])
row0.T.dot(row1)
array([[0.]])
Let’s check that
and thus
A.T.dot(A)
array([[1., 0.],
[0., 1.]])
A.T
array([[ 0.96496603, -0.26237485],
[ 0.26237485, 0.96496603]])
numpy.linalg.inv(A)
array([[ 0.96496603, -0.26237485],
[ 0.26237485, 0.96496603]])
Everything is correct!
Conclusion#
In this chapter we saw different interesting type of matrices with specific properties. It is generally useful to recall them while we deal with this kind of matrices.
In the next chapter we will saw a central idea in linear algebra: the eigendecomposition. Keep reading!