Linear Regression, Part 2#
In this chapter we will start with a quick walkthrough of the mathematics behind this well-known problem, before moving on to see how linear models can be generalized to account for more complicated patterns in data.
We begin with the standard imports:
Show code cell source
%matplotlib inline
# Import necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.preprocessing import PolynomialFeatures
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.pipeline import make_pipeline
# Set plot style
sns.set_style("whitegrid")
plt.rcParams['figure.figsize'] = (12, 8)
Simple Linear Regression#
We will start with the most familiar linear regression, a straight-line fit to data. A straight-line fit is a model of the form:
where \(a\) is commonly known as the slope, and \(b\) is commonly known as the intercept.
Consider the following data, which is scattered about a line with a slope of 2 and an intercept of –5 (see the following figure):
rng = np.random.RandomState(1)
x = 10 * rng.rand(50)
y = 2 * x - 5 + rng.randn(50)
plt.scatter(x, y);
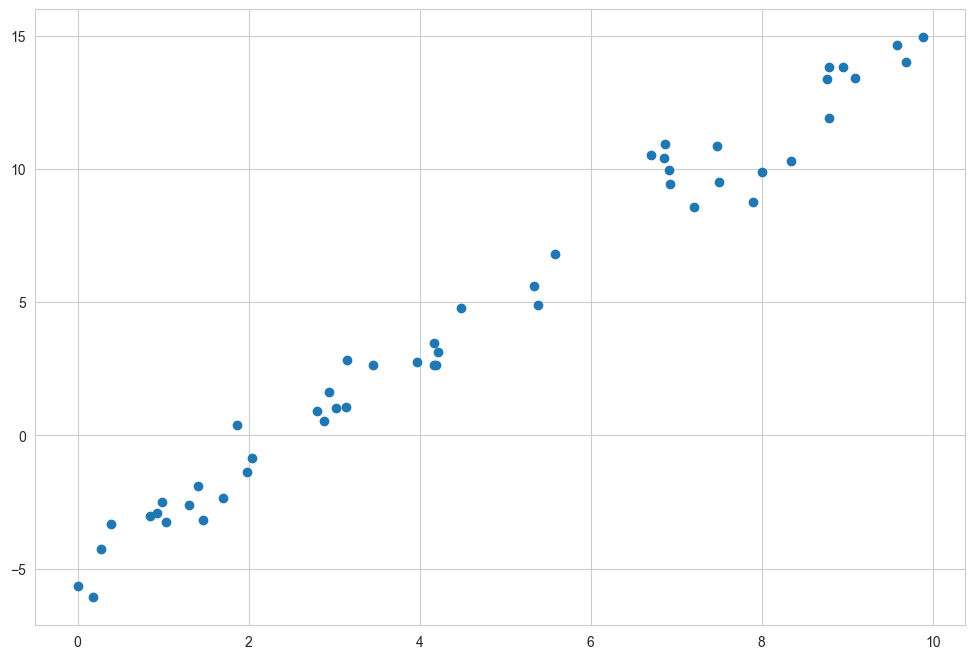
We can use Scikit-Learn’s LinearRegression estimator to fit this data and construct the best-fit line, as shown in the following figure:
Show code cell source
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model.fit(x[:, np.newaxis], y)
xfit = np.linspace(0, 10, 1000)
yfit = model.predict(xfit[:, np.newaxis])
plt.scatter(x, y)
plt.plot(xfit, yfit);
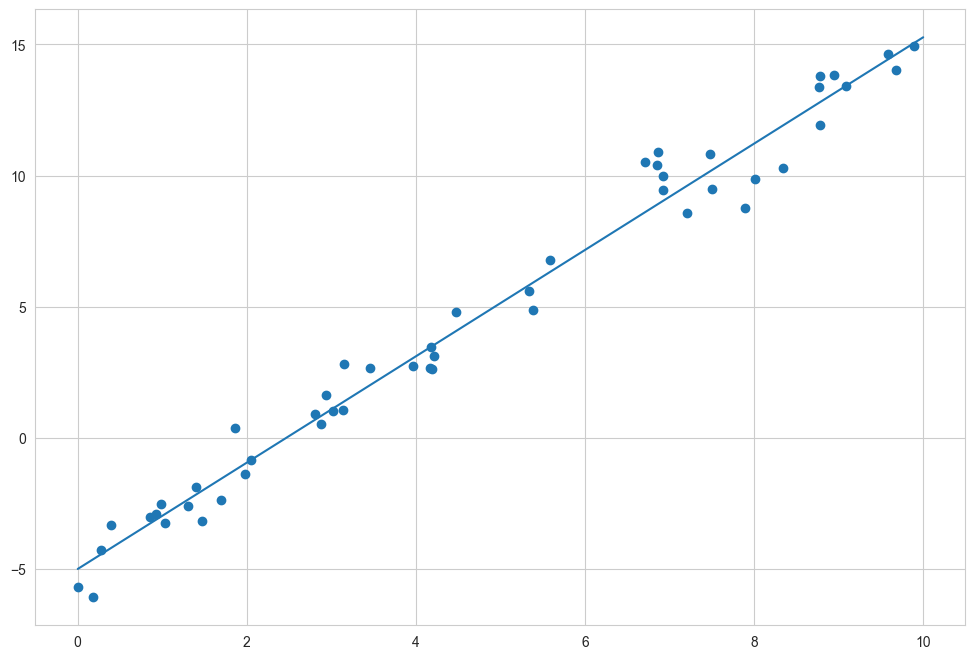
The slope and intercept of the data are contained in the model’s fit parameters, which in Scikit-Learn are always marked by a trailing underscore.
Here the relevant parameters are coef_ and intercept_:
Show code cell source
print("Model slope: ", model.coef_[0])
print("Model intercept:", model.intercept_)
Model slope: 2.0272088103606944
Model intercept: -4.9985770855532
We see that the results are very close to the values used to generate the data, as we might hope.
The LinearRegression estimator is much more capable than this, however—in addition to simple straight-line fits, it can also handle multidimensional linear models of the form:
where there are multiple \(x\) values. Geometrically, this is akin to fitting a plane to points in three dimensions, or fitting a hyperplane to points in higher dimensions.
The multidimensional nature of such regressions makes them more difficult to visualize, but we can see one of these fits in action by building some example data, using NumPy’s matrix multiplication operator:
rng = np.random.RandomState(1)
X = 10 * rng.rand(100, 3)
y = 0.5 + np.dot(X, [1.5, -2., 1.])
model.fit(X, y)
print(model.intercept_)
print(model.coef_)
0.5000000000000033
[ 1.5 -2. 1. ]
Here the \(y\) data is constructed from a linear combination of three random \(x\) values, and the linear regression recovers the coefficients used to construct the data.
In this way, we can use the single LinearRegression estimator to fit lines, planes, or hyperplanes to our data.
It still appears that this approach would be limited to strictly linear relationships between variables, but it turns out we can relax this as well.
Polynomial Regression#
One trick you can use to adapt linear regression to nonlinear relationships between variables is to transform the data according to basis functions.
We have seen one version of this before, in the PolynomialRegression pipeline used in Hyperparameters and Model Validation and Feature Engineering.
The idea is to take our multidimensional linear model:
and build the \(x_1, x_2, x_3,\) and so on from our single-dimensional input \(x\). That is, we let \(x_n = f_n(x)\), where \(f_n()\) is some function that transforms our data.
For example, if \(f_n(x) = x^n\), our model becomes a polynomial regression:
Notice that this is still a linear model—the linearity refers to the fact that the coefficients \(a_n\) never multiply or divide each other. What we have effectively done is taken our one-dimensional \(x\) values and projected them into a higher dimension, so that a linear fit can fit more complicated relationships between \(x\) and \(y\).
Polynomial Basis Functions#
This polynomial projection is useful enough that it is built into Scikit-Learn, using the PolynomialFeatures transformer:
from sklearn.preprocessing import PolynomialFeatures
x = np.array([2, 3, 4])
poly = PolynomialFeatures(3, include_bias=False)
poly.fit_transform(x[:, None])
array([[ 2., 4., 8.],
[ 3., 9., 27.],
[ 4., 16., 64.]])
We see here that the transformer has converted our one-dimensional array into a three-dimensional array, where each column contains the exponentiated value. This new, higher-dimensional data representation can then be plugged into a linear regression.
As we saw in Feature Engineering, the cleanest way to accomplish this is to use a pipeline. Let’s make a 7th-degree polynomial model in this way:
from sklearn.pipeline import make_pipeline
poly_model = make_pipeline(PolynomialFeatures(7),
LinearRegression())
With this transform in place, we can use the linear model to fit much more complicated relationships between \(x\) and \(y\). For example, here is a sine wave with noise (see the following figure):
# rng = np.random.RandomState(1)
# x = 10 * rng.rand(50)
# y = np.sin(x) + 0.1 * rng.randn(50)
n_samples = 100
x = np.sort(np.random.uniform(0, 1, n_samples))
y = np.sin(2 * np.pi * x) + 0.3 * np.random.randn(n_samples)
poly_model.fit(x[:, np.newaxis], y)
yfit = poly_model.predict(x[:, np.newaxis])
plt.scatter(x, y)
plt.plot(x, yfit)
[<matplotlib.lines.Line2D at 0x219ae4a7430>]
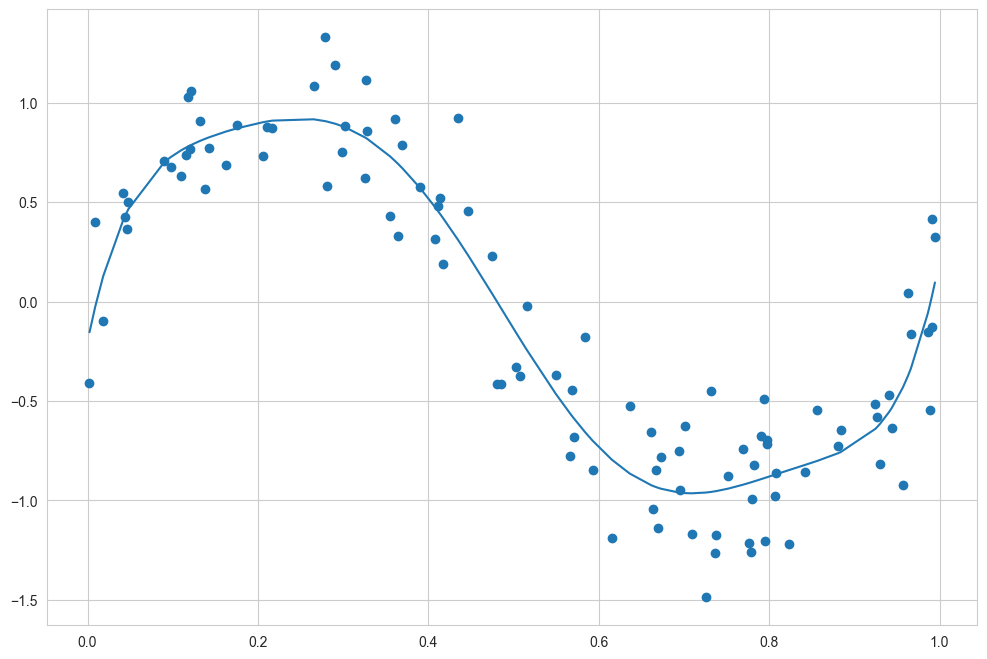
Our linear model, through the use of seventh-order polynomial basis functions, can provide an excellent fit to this nonlinear data!
Regularization#
The introduction of basis functions into our linear regression makes the model much more flexible, but it also can very quickly lead to overfitting (refer back to Hyperparameters and Model Validation for a discussion of this).
The lower panel of this figure shows the amplitude of the basis function at each location. This is typical overfitting behavior when basis functions overlap: the coefficients of adjacent basis functions blow up and cancel each other out. We know that such behavior is problematic, and it would be nice if we could limit such spikes explicitly in the model by penalizing large values of the model parameters. Such a penalty is known as regularization, and comes in several forms.
Ridge Regression (\(L_2\) Regularization)#
Perhaps the most common form of regularization is known as ridge regression or \(L_2\) regularization (sometimes also called Tikhonov regularization). This proceeds by penalizing the sum of squares (2-norms) of the model coefficients \(\theta_n\). In this case, the penalty on the model fit would be:
where \(\alpha\) is a free parameter that controls the strength of the penalty.
This type of penalized model is built into Scikit-Learn with the Ridge estimator (see the following figure):
The \(\alpha\) parameter is essentially a knob controlling the complexity of the resulting model. In the limit \(\alpha \to 0\), we recover the standard linear regression result; in the limit \(\alpha \to \infty\), all model responses will be suppressed. One advantage of ridge regression in particular is that it can be computed very efficiently—at hardly more computational cost than the original linear regression model.
Generate Synthetic Data
Let’s create some synthetic data that follows a non-linear pattern with some noise:
Show code cell source
# Set random seed for reproducibility
np.random.seed(42)
# Generate synthetic data
n_samples = 100
X = np.sort(np.random.uniform(0, 1, n_samples))
y = np.sin(2 * np.pi * X) + 0.3 * np.random.randn(n_samples)
# Create a dataframe
data = pd.DataFrame({
'x': X,
'y': y
})
# Generate polynomial features
for i in range(2, 16):
data['x_%d' % i] = data['x'] ** i
# Plot the data
plt.figure(figsize=(10, 6))
plt.scatter(data['x'], data['y'], color='blue', s=30, alpha=0.6)
plt.title('Synthetic Data')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
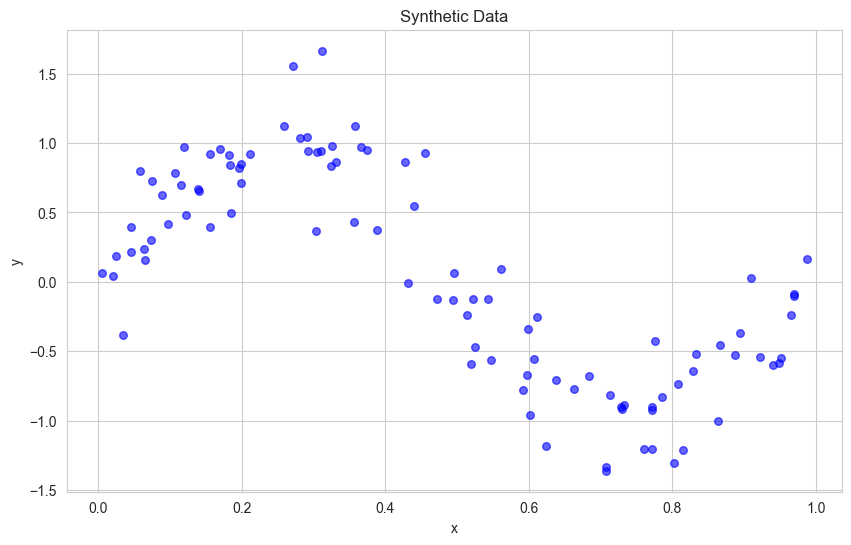
Understanding Overfitting#
Let’s implement functions to fit both standard linear regression and Ridge regression with polynomial features:
Show code cell source
def linear_regression(data, power, models_to_plot):
# Initialize predictors
predictors = ['x']
if power >= 2:
predictors.extend(['x_%d' % i for i in range(2, power+1)])
# Fit the model
linreg = LinearRegression()
linreg.fit(data[predictors], data['y'])
y_pred = linreg.predict(data[predictors])
# Check if a plot is to be made for the entered power
if power in models_to_plot:
plt.subplot(models_to_plot[power])
plt.tight_layout()
plt.plot(data['x'], y_pred, 'r-', linewidth=2)
plt.plot(data['x'], data['y'], 'b.', alpha=0.6)
plt.title('Linear Regression with Polynomial Degree: %d' % power)
# Return the result in pre-defined format
rss = sum((y_pred - data['y'])**2)
ret = [rss]
ret.extend([linreg.intercept_])
ret.extend(linreg.coef_)
# Pad with zeros to match the number of columns in the DataFrame
# We need 17 values total: 'rss', 'intercept', and 15 coefficients
while len(ret) < 17:
ret.append(0)
return ret[:17] # Ensure we return exactly the right number of values
def ridge_regression(data, power, alpha, models_to_plot):
# Initialize predictors
predictors = ['x']
if power >= 2:
predictors.extend(['x_%d' % i for i in range(2, power+1)])
# Fit the model
ridgereg = Ridge(alpha=alpha)
ridgereg.fit(data[predictors], data['y'])
y_pred = ridgereg.predict(data[predictors])
# Check if a plot is to be made for the entered power
if power in models_to_plot:
# Use subplot position as a single integer (e.g., 1, 2, 3, 4, 5)
# and convert it to the correct format for plt.subplot
subplot_pos = models_to_plot[power]
plt.subplot(2, 3, subplot_pos) # 2 rows, 3 columns, position subplot_pos
plt.plot(data['x'], y_pred, 'r-', linewidth=2)
plt.plot(data['x'], data['y'], 'b.', alpha=0.6)
plt.title(f'Ridge Regression with Polynomial Degree: {power}, Alpha: {alpha:.2f}')
# Return the result in pre-defined format
rss = sum((y_pred - data['y'])**2)
ret = [rss]
ret.extend([ridgereg.intercept_])
ret.extend(ridgereg.coef_)
# Pad with zeros to match the number of columns in the DataFrame
while len(ret) < power + 2: # rss, intercept, and power coefficients
ret.append(0)
return ret[:power + 2] # Ensure we return exactly the right number of values
Comparing Linear Regression with Different Polynomial Degrees#
Let’s visualize how standard linear regression behaves with increasing polynomial degrees:
Show code cell source
# Initialize a dataframe to store the results
# This should have 17 columns: 'rss', 'intercept', and 15 coefficient columns
linear_model = pd.DataFrame(columns=['rss', 'intercept'] + ['coef_x_%d' % i for i in range(1, 16)])
# Print the number of columns to verify
print(f"Number of columns in DataFrame: {len(linear_model.columns)}")
# Set the powers for which we want to plot the models
models_to_plot = {1: 131, 3: 132, 15: 133}
# Fit linear regression models with different powers
plt.figure(figsize=(12, 5))
for power in range(1, 16):
linear_model.loc[power] = linear_regression(data, power, models_to_plot)
plt.tight_layout()
plt.show()
Number of columns in DataFrame: 17
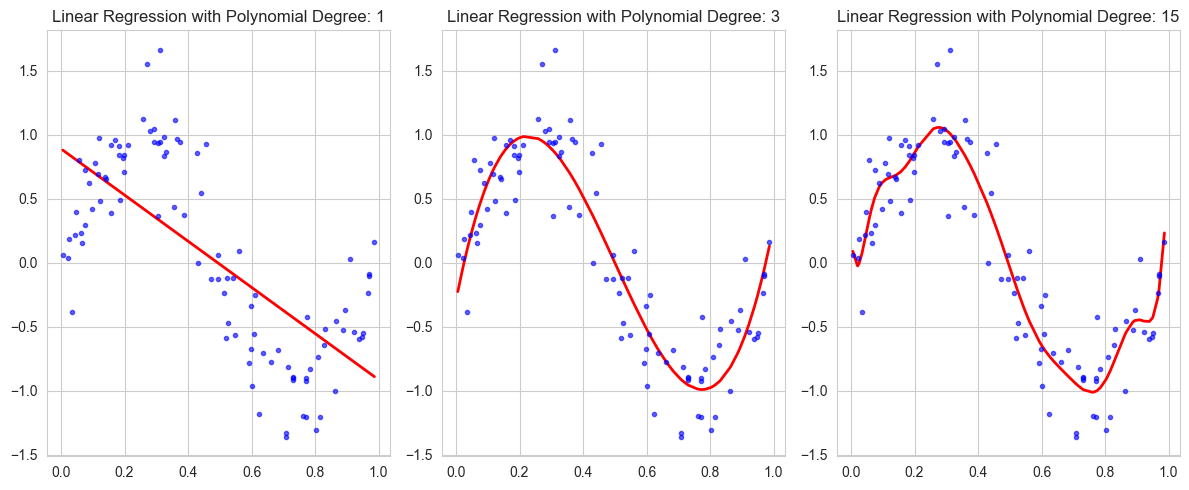
Analyzing Model Complexity and Overfitting#
In this example, we’ll explore how increasing the complexity of a polynomial regression model affects its performance on both training and test data. We’ll:
Split our synthetic data into training (50%) and test (50%) sets
Fit polynomial regression models with degrees from 1 to 15
Visualize the model predictions for degrees 1, 3, 6, 12, and 15
Plot the training and test errors (RSS) against model complexity
Key observations to look for:
How well does each model fit the training data?
Does increasing polynomial degree always lead to better predictions?
Can you identify where overfitting begins to occur?
Notice how the training error consistently decreases while the test error might start increasing
Show code cell source
# Split the data into training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data['x'], data['y'], test_size=0.5, random_state=42)
# Create training and testing dataframes
train_data = pd.DataFrame({'x': X_train, 'y': y_train})
test_data = pd.DataFrame({'x': X_test, 'y': y_test})
# Generate polynomial features for both sets
for i in range(2, 16):
train_data[f'x_{i}'] = train_data['x'] ** i
test_data[f'x_{i}'] = test_data['x'] ** i
# Initialize a dataframe to store the results
linear_model = pd.DataFrame(columns=['train_rss', 'test_rss', 'intercept'] + [f'coef_x_{i}' for i in range(1, 16)])
# Set the powers for which we want to plot the models
models_to_plot = {1: 231, 3: 232, 6: 233, 12: 234, 15:235}
# Create figure with more subplots
plt.figure(figsize=(15, 10))
# Lists to store errors for plotting
train_errors = []
test_errors = []
# Fit linear regression models with different powers
for power in range(1, 16):
# Initialize predictors
predictors = ['x']
if power >= 2:
predictors.extend([f'x_{i}' for i in range(2, power+1)])
# Fit the model
linreg = LinearRegression()
linreg.fit(train_data[predictors], train_data['y'])
# Make predictions
y_train_pred = linreg.predict(train_data[predictors])
y_test_pred = linreg.predict(test_data[predictors])
# Calculate RSS for both sets
train_rss = sum((y_train_pred - train_data['y'])**2)
test_rss = sum((y_test_pred - test_data['y'])**2)
# Store errors for plotting
train_errors.append(train_rss)
test_errors.append(test_rss)
# Store results
ret = [train_rss, test_rss, linreg.intercept_] + list(linreg.coef_) + [0] * (15 - power)
linear_model.loc[power] = ret
# Plot if this is one of our selected models
if power in models_to_plot:
plt.subplot(models_to_plot[power])
# Sort for proper line plotting
train_points = pd.DataFrame({'x': train_data['x'], 'y_pred': y_train_pred}).sort_values('x')
test_points = pd.DataFrame({'x': test_data['x'], 'y_pred': y_test_pred}).sort_values('x')
plt.plot(train_points['x'], train_points['y_pred'], 'r-', linewidth=2, label='Prediction')
plt.scatter(train_data['x'], train_data['y'], color='blue', s=30, alpha=0.6, label='Train')
plt.scatter(test_data['x'], test_data['y'], color='green', s=30, alpha=0.6, label='Test')
plt.title(f'Polynomial Degree: {power}')
plt.legend()
# Add the error plot
plt.subplot(236)
plt.plot(range(1, 16), train_errors, 'b-', label='Training Error')
plt.plot(range(1, 16), test_errors, 'r-', label='Test Error')
plt.xlabel('Polynomial Degree')
plt.ylabel('RSS')
plt.title('Training vs Testing Error')
plt.legend()
plt.tight_layout()
plt.show()

Ridge regression adds a penalty term to the cost function, which is the sum of the squared coefficients multiplied by a regularization parameter alpha. This helps prevent overfitting by keeping the coefficients small.
The cost function for Ridge regression is:
Where:
MSE is the mean squared error
α (alpha) is the regularization parameter
θᵢ are the model coefficients (excluding the intercept)
Let’s compare Ridge regression with different alpha values for a high-degree polynomial:
Show code cell source
# Initialize a dataframe to store the results
ridge_models = {}
alphas = [0, 0.01, 1]
power = 12 # Using a high polynomial degree to demonstrate overfitting
plt.figure(figsize=(15, 10))
counter = 1
for alpha in alphas:
ridge_models[alpha] = pd.DataFrame(columns=['rss', 'intercept'] + ['coef_x_%d' % i for i in range(1, power+1)])
# Pass the counter as the subplot position (1, 2, 3, 4, 5)
ridge_models[alpha].loc[power] = ridge_regression(data, power, alpha, {power: counter})
counter += 1
plt.tight_layout()
plt.show()
c:\Users\m.amintoosi\.conda\envs\pth-gpu\lib\site-packages\sklearn\linear_model\_ridge.py:215: LinAlgWarning: Ill-conditioned matrix (rcond=1.187e-18): result may not be accurate.
return linalg.solve(A, Xy, assume_a="pos", overwrite_a=True).T

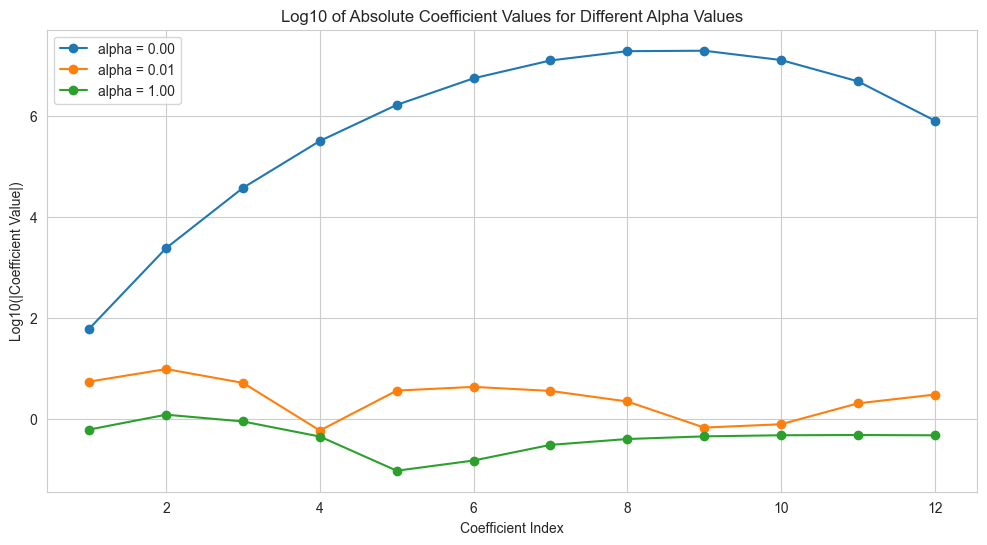
Visualizing the Effect of Alpha on Coefficients#
Let’s see how the coefficients change with different alpha values:
Show code cell source
# Extract the coefficients for different alpha values
coef_matrix = pd.DataFrame(index=range(1, power+1))
for alpha in alphas:
# Take the absolute value and then log transform the coefficients
coef_matrix['alpha = %.2f' % alpha] = np.log10(np.abs(ridge_models[alpha].loc[power][2:]) + 1e-10)
# Plot the log-transformed coefficient values
plt.figure(figsize=(12, 6))
for alpha in alphas:
# Plot log10 of absolute coefficient values
plt.plot(range(1, power+1), np.log10(np.abs(ridge_models[alpha].loc[power][2:]) + 1e-10),
'o-', label='alpha = %.2f' % alpha)
plt.title('Log10 of Absolute Coefficient Values for Different Alpha Values')
plt.xlabel('Coefficient Index')
plt.ylabel('Log10(|Coefficient Value|)')
plt.legend()
plt.grid(True)
plt.show()
Lasso Regression (\(L_1\) Regularization)#
Another common type of regularization is known as lasso regression or L~1~ regularization involves penalizing the sum of absolute values (1-norms) of regression coefficients:
Though this is conceptually very similar to ridge regression, the results can differ surprisingly. For example, due to its construction, lasso regression tends to favor sparse models where possible: that is, it preferentially sets many model coefficients to exactly zero.
With the lasso regression penalty, the majority of the coefficients are exactly zero, with the functional behavior being modeled by a small subset of the available basis functions. As with ridge regularization, the \(\alpha\) parameter tunes the strength of the penalty and should be determined via, for example, cross-validation (refer back to Hyperparameters and Model Validation for a discussion of this).
For further information about related materials see Appendix: Mathematics and Machine Learning
Example: Predicting Bicycle Traffic#
As an example, let’s take a look at whether we can predict the number of bicycle trips across Seattle’s Fremont Bridge based on weather, season, and other factors. We already saw this data in Working With Time Series, but here we will join the bike data with another dataset and try to determine the extent to which weather and seasonal factors—temperature, precipitation, and daylight hours—affect the volume of bicycle traffic through this corridor. Fortunately, the National Oceanic and Atmospheric Administration (NOAA) makes its daily weather station data available—I used station ID USW00024233—and we can easily use Pandas to join the two data sources. We will perform a simple linear regression to relate weather and other information to bicycle counts, in order to estimate how a change in any one of these parameters affects the number of riders on a given day.
In particular, this is an example of how the tools of Scikit-Learn can be used in a statistical modeling framework, in which the parameters of the model are assumed to have interpretable meaning. As discussed previously, this is not a standard approach within machine learning, but such interpretation is possible for some models.
Let’s start by loading the two datasets, indexing by date:
# These files are included in the course repository
# url = 'https://raw.githubusercontent.com/jakevdp/bicycle-data/main'
# !curl -O {url}/FremontBridge.csv
# !curl -O {url}/SeattleWeather.csv
import pandas as pd
counts = pd.read_csv('FremontBridge.csv',
index_col='Date', parse_dates=True)
counts.head()
C:\Users\m.amintoosi\AppData\Local\Temp\ipykernel_12700\62250122.py:2: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
counts = pd.read_csv('FremontBridge.csv',
| Fremont Bridge Total | Fremont Bridge East Sidewalk | Fremont Bridge West Sidewalk | |
|---|---|---|---|
| Date | |||
| 2019-11-01 00:00:00 | 12.0 | 7.0 | 5.0 |
| 2019-11-01 01:00:00 | 7.0 | 0.0 | 7.0 |
| 2019-11-01 02:00:00 | 1.0 | 0.0 | 1.0 |
| 2019-11-01 03:00:00 | 6.0 | 6.0 | 0.0 |
| 2019-11-01 04:00:00 | 6.0 | 5.0 | 1.0 |
weather = pd.read_csv('SeattleWeather.csv',
index_col='DATE', parse_dates=True)
weather.head()
| STATION | NAME | AWND | FMTM | PGTM | PRCP | SNOW | SNWD | TAVG | TMAX | ... | WT04 | WT05 | WT08 | WT09 | WT13 | WT14 | WT16 | WT17 | WT18 | WT22 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DATE | |||||||||||||||||||||
| 2012-01-01 | USW00024233 | SEATTLE TACOMA AIRPORT, WA US | 10.51 | NaN | NaN | 0.00 | 0.0 | 0.0 | NaN | 55 | ... | NaN | NaN | NaN | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN |
| 2012-01-02 | USW00024233 | SEATTLE TACOMA AIRPORT, WA US | 10.07 | NaN | NaN | 0.43 | 0.0 | 0.0 | NaN | 51 | ... | NaN | NaN | NaN | NaN | 1.0 | NaN | 1.0 | NaN | NaN | NaN |
| 2012-01-03 | USW00024233 | SEATTLE TACOMA AIRPORT, WA US | 5.14 | NaN | NaN | 0.03 | 0.0 | 0.0 | NaN | 53 | ... | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 | NaN | NaN | NaN |
| 2012-01-04 | USW00024233 | SEATTLE TACOMA AIRPORT, WA US | 10.51 | NaN | NaN | 0.80 | 0.0 | 0.0 | NaN | 54 | ... | NaN | NaN | NaN | NaN | 1.0 | NaN | 1.0 | NaN | NaN | NaN |
| 2012-01-05 | USW00024233 | SEATTLE TACOMA AIRPORT, WA US | 13.65 | NaN | NaN | 0.05 | 0.0 | 0.0 | NaN | 48 | ... | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 | NaN | NaN | NaN |
5 rows × 28 columns
For simplicity, let’s look at data prior to 2020 in order to avoid the effects of the COVID-19 pandemic, which significantly affected commuting patterns in Seattle:
counts = counts[counts.index < "2020-01-01"]
weather = weather[weather.index < "2020-01-01"]
Next we will compute the total daily bicycle traffic, and put this in its own DataFrame:
daily = counts.resample('d').sum()
daily['Total'] = daily.sum(axis=1)
daily = daily[['Total']] # remove other columns
We saw previously that the patterns of use generally vary from day to day. Let’s account for this in our data by adding binary columns that indicate the day of the week:
days = ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
for i in range(7):
daily[days[i]] = (daily.index.dayofweek == i).astype(float)
Similarly, we might expect riders to behave differently on holidays; let’s add an indicator of this as well:
from pandas.tseries.holiday import USFederalHolidayCalendar
cal = USFederalHolidayCalendar()
holidays = cal.holidays('2012', '2020')
daily = daily.join(pd.Series(1, index=holidays, name='holiday'))
daily['holiday'].fillna(0, inplace=True)
C:\Users\m.amintoosi\AppData\Local\Temp\ipykernel_12700\3085141007.py:5: FutureWarning: A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
daily['holiday'].fillna(0, inplace=True)
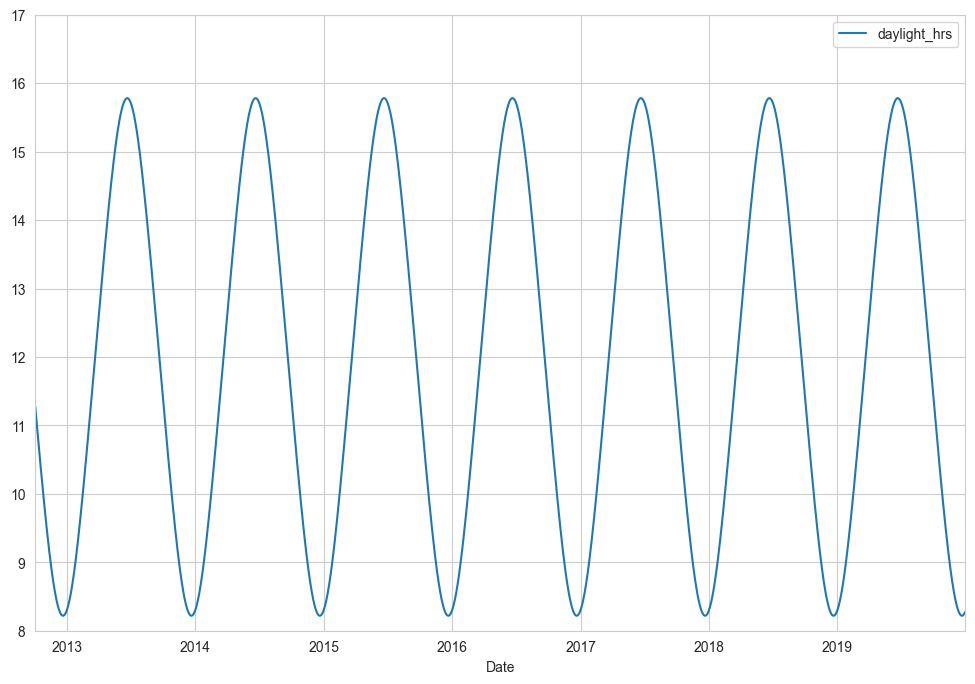
We also might suspect that the hours of daylight would affect how many people ride. Let’s use the standard astronomical calculation to add this information (see the following figure):
def hours_of_daylight(date, axis=23.44, latitude=47.61):
"""Compute the hours of daylight for the given date"""
days = (date - pd.Timestamp(2000, 12, 21)).days
m = (1. - np.tan(np.radians(latitude))
* np.tan(np.radians(axis) * np.cos(days * 2 * np.pi / 365.25)))
return 24. * np.degrees(np.arccos(1 - np.clip(m, 0, 2))) / 180.
daily['daylight_hrs'] = list(map(hours_of_daylight, daily.index))
daily[['daylight_hrs']].plot()
plt.ylim(8, 17)
(8.0, 17.0)
We can also add the average temperature and total precipitation to the data. In addition to the inches of precipitation, let’s add a flag that indicates whether a day is dry (has zero precipitation):
weather['Temp (F)'] = 0.5 * (weather['TMIN'] + weather['TMAX'])
weather['Rainfall (in)'] = weather['PRCP']
weather['dry day'] = (weather['PRCP'] == 0).astype(int)
daily = daily.join(weather[['Rainfall (in)', 'Temp (F)', 'dry day']])
Finally, let’s add a counter that increases from day 1, and measures how many years have passed. This will let us measure any observed annual increase or decrease in daily crossings:
daily['annual'] = (daily.index - daily.index[0]).days / 365.
Now our data is in order, and we can take a look at it:
daily.head()
| Total | Mon | Tue | Wed | Thu | Fri | Sat | Sun | holiday | daylight_hrs | Rainfall (in) | Temp (F) | dry day | annual | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | ||||||||||||||
| 2012-10-03 | 14084.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 11.277359 | 0.0 | 56.0 | 1 | 0.000000 |
| 2012-10-04 | 13900.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 11.219142 | 0.0 | 56.5 | 1 | 0.002740 |
| 2012-10-05 | 12592.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 11.161038 | 0.0 | 59.5 | 1 | 0.005479 |
| 2012-10-06 | 8024.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 11.103056 | 0.0 | 60.5 | 1 | 0.008219 |
| 2012-10-07 | 8568.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 11.045208 | 0.0 | 60.5 | 1 | 0.010959 |
With this in place, we can choose the columns to use, and fit a linear regression model to our data.
We will set fit_intercept=False, because the daily flags essentially operate as their own day-specific intercepts:
# Drop any rows with null values
daily.dropna(axis=0, how='any', inplace=True)
column_names = ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun',
'holiday', 'daylight_hrs', 'Rainfall (in)',
'dry day', 'Temp (F)', 'annual']
X = daily[column_names]
y = daily['Total']
model = LinearRegression(fit_intercept=False)
model.fit(X, y)
daily['predicted'] = model.predict(X)
Finally, we can compare the total and predicted bicycle traffic visually (see the following figure):
daily[['Total', 'predicted']].plot(alpha=0.5);
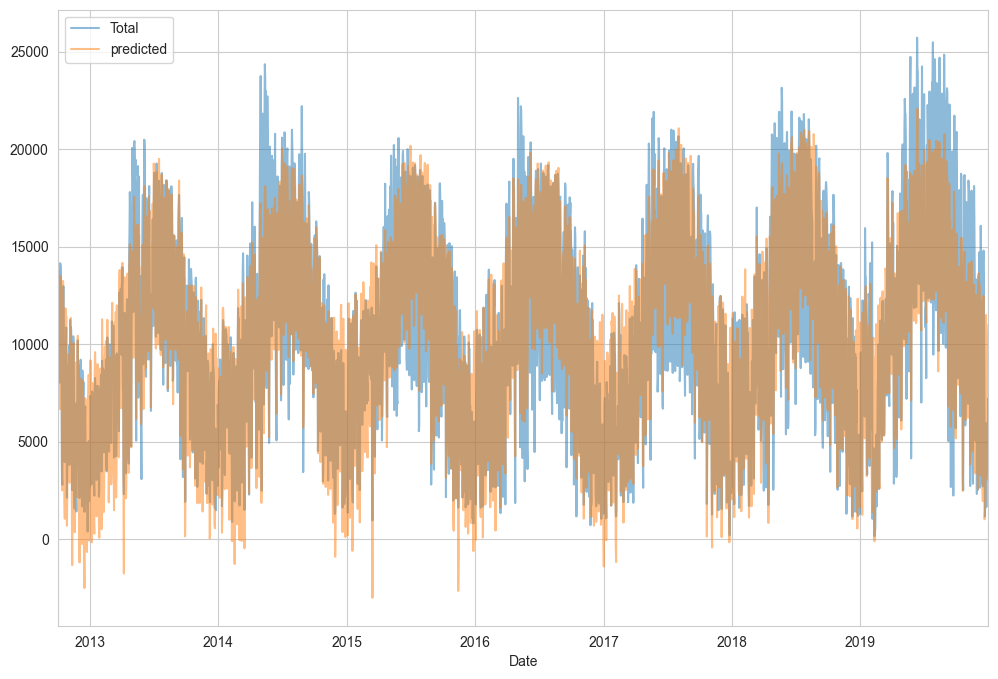
From the fact that the data and model predictions don’t line up exactly, it is evident that we have missed some key features. Either our features are not complete (i.e., people decide whether to ride to work based on more than just these features), or there are some nonlinear relationships that we have failed to take into account (e.g., perhaps people ride less at both high and low temperatures). Nevertheless, our rough approximation is enough to give us some insights, and we can take a look at the coefficients of the linear model to estimate how much each feature contributes to the daily bicycle count:
params = pd.Series(model.coef_, index=X.columns)
params
Mon -3309.953439
Tue -2860.625060
Wed -2962.889892
Thu -3480.656444
Fri -4836.064503
Sat -10436.802843
Sun -10795.195718
holiday -5006.995232
daylight_hrs 409.146368
Rainfall (in) -2789.860745
dry day 2111.069565
Temp (F) 179.026296
annual 324.437749
dtype: float64
These numbers are difficult to interpret without some measure of their uncertainty. We can compute these uncertainties quickly using bootstrap resamplings of the data:
from sklearn.utils import resample
np.random.seed(1)
err = np.std([model.fit(*resample(X, y)).coef_
for i in range(1000)], 0)
With these errors estimated, let’s again look at the results:
print(pd.DataFrame({'effect': params.round(0),
'uncertainty': err.round(0)}))
effect uncertainty
Mon -3310.0 265.0
Tue -2861.0 274.0
Wed -2963.0 268.0
Thu -3481.0 268.0
Fri -4836.0 261.0
Sat -10437.0 259.0
Sun -10795.0 267.0
holiday -5007.0 401.0
daylight_hrs 409.0 26.0
Rainfall (in) -2790.0 186.0
dry day 2111.0 101.0
Temp (F) 179.0 7.0
annual 324.0 22.0
The effect column here, roughly speaking, shows how the number of riders is affected by a change of the feature in question.
For example, there is a clear divide when it comes to the day of the week: there are thousands fewer riders on weekends than on weekdays.
We also see that for each additional hour of daylight, 409 ± 26 more people choose to ride; a temperature increase of one degree Fahrenheit encourages 179 ± 7 people to grab their bicycle; a dry day means an average of 2,111 ± 101 more riders,
and every inch of rainfall leads 2,790 ± 186 riders to choose another mode of transport.
Once all these effects are accounted for, we see a modest increase of 324 ± 22 new daily riders each year.
Our simple model is almost certainly missing some relevant information. For example, as mentioned earlier, nonlinear effects (such as effects of precipitation and cold temperature) and nonlinear trends within each variable (such as disinclination to ride at very cold and very hot temperatures) cannot be accounted for in a simple linear model. Additionally, we have thrown away some of the finer-grained information (such as the difference between a rainy morning and a rainy afternoon), and we have ignored correlations between days (such as the possible effect of a rainy Tuesday on Wednesday’s numbers, or the effect of an unexpected sunny day after a streak of rainy days). These are all potentially interesting effects, and you now have the tools to begin exploring them if you wish!
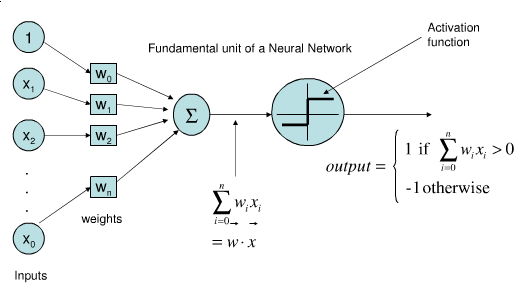
Perceptron#
Represents a single neuron (node) with inputs \(x_i\), a bias \(w_0\), and output \(y\)
Each connection has a (synaptic) weight \(w_i\). The node outputs \(\hat{y} = \sum_{i}^n x_{i}w_i + w_0\)
The activation function predicts 1 if \(\mathbf{xw} + w_0 > 0\), -1 otherwise
Weights can be learned with (stochastic) gradient descent and Hinge(0) loss
Updated only on misclassification, corrects output by \(\pm1\)
\[\mathcal{L}_{Perceptron} = max(0,-y_i (\mathbf{w}\mathbf{x_i} + w_0))\]\[\begin{split}\frac{\partial \mathcal{L_{Perceptron}}}{\partial w_i} = \begin{cases}-y_i x_i & y_i (\mathbf{w}\mathbf{x_i} + w_0) < 0\\ 0 & \text{otherwise} \\ \end{cases}\end{split}\]
Logistic regression#
Aims to predict the probability that a point belongs to the positive class
Converts target values {negative (blue), positive (red)} to {0,1}
Fits a logistic (or sigmoid or S curve) function through these points
Maps (-Inf,Inf) to a probability [0,1]
\[ \hat{y} = \textrm{logistic}(f_{\theta}(\mathbf{x})) = \frac{1}{1+e^{-f_{\theta}(\mathbf{x})}} \]E.g. in 1D: \( \textrm{logistic}(x_1w_1+w_0) = \frac{1}{1+e^{-x_1w_1-w_0}} \)